Whisper Tabanlı Konuşma ve NLP Sistemi
Whisper transkripsiyonu, prompt tabanlı özetleme ve Hugging Face model entegrasyonu etrafında sunucu taraflı bir konuşma/metin hattı kurdum.
Diller
TR / EN
Konuşma desteği
Veri hattı
STT + NLP
Sesten metin içgörüsü
Dağıtım
Kendi sunucunda
Sunucu tarafı odak
Proje Galerisi
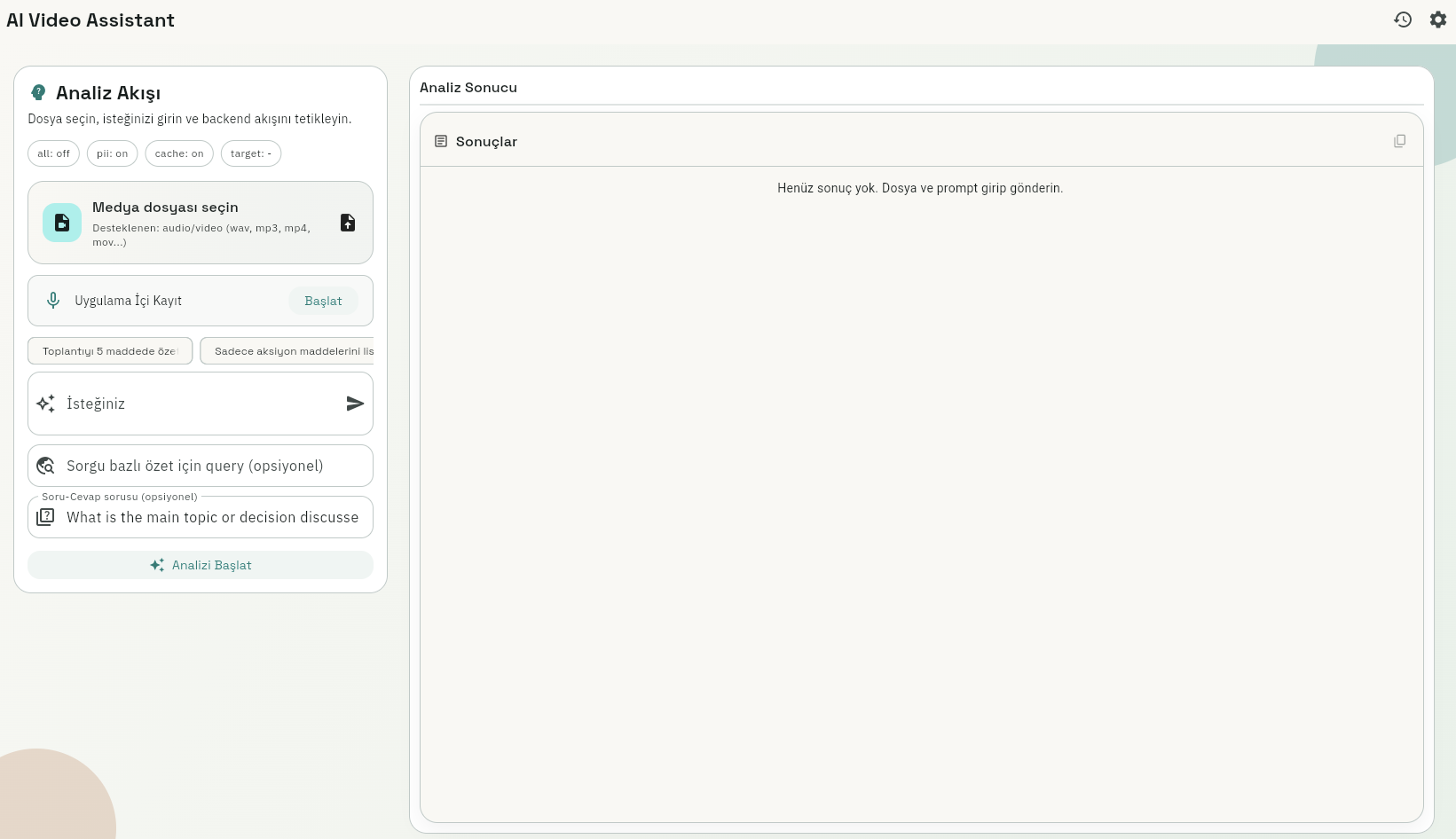

1/2
Problem
Konuşma iş akışları çoğu zaman harici SaaS katmanlarına bağlı kalıyor; bu da yerel denemeyi, gizlilik odaklı dağıtımı ve özel metin işlemeyi zorlaştırıyor.
Zorluk
Sistemin Türkçe ve İngilizce girdileri desteklemesi; transkripsiyon, özetleme ve sonraki NLP adımlarını modüler tutması gerekiyordu.
Mimari
Parçalar nasıl bir araya geliyor?
Ses Whisper transkripsiyon aşamasına girer, dil farkındalığı olan metin normalizasyonundan geçer, ardından prompt tabanlı özetleme ve opsiyonel model adaptörlerine akar.
Mimari Görünüm
Sistem yapısı ve karar akışı
Ses Girdisi
Türkçe ve İngilizce konuşma dosyaları.
Whisper STT
Sunucu taraflı transkripsiyon ve normalizasyon.
NLP Katmanı
Prompt özetleme ve Hugging Face adaptörleri.
Veri Seti / Girdiler
- Özetleme ve analiz gibi sonraki metin işleme ihtiyaçları olan Türkçe ve İngilizce ses girdileri.
Teknik Kararlar
- Transkripsiyon, normalizasyon, özetleme ve model adaptörlerini modüler tuttum.
- Dağıtım kısıtlarını veri hattı tasarımının parçası olarak ele aldım.
- Tekrarlanabilir NLP çıktıları için prompt şablonları destekledim.
Uygulama Detayları
- Whisper sunucu tarafında speech-to-text aşamasını yönetir.
- Metin, prompt tabanlı özetlemeden önce normalize edilir.
- Hugging Face adaptörleri görev odaklı NLP işleme için eklenebilir.
Metrikler / Sonuçlar
- Veri hattı, genişletilebilir NLP sonrası işleme adımlarıyla yerel/sunucu taraflı speech-to-text akışları için sağlam bir temel oluşturur.
Çıkarımlar
- Speech-to-text kalitesi, kullanıcıya görünen iş akışının yalnızca bir parçasıdır.
- Dil farkındalığı olan temizlik sonraki model davranışını iyileştirir.
- Kendi sunucunda çalıştırmak gözlemlenebilirliği ve özelleştirmeyi kolaylaştırır.
Gelecek İyileştirmeler
- Çok konuşmacılı sesler için diarization eklemek.
- Uzun transkripsiyonlar için asenkron job queue kullanmak.
- Transkript versiyonlarını ve prompt çıktılarını inceleme için saklamak.